BLIP
type
status
date
slug
summary
tags
category
icon
password
模型
img
img
摘要
- 同时完成vision-language模型的理解与生成任务
- 通过bootstrap的标题来规避web上大量noisy的数据
介绍
以往模型的两个局限
- 模型方面
- encoder-based
- 无法完成文本生成任务
- encoder-decoder
- 不适合图文检索任务
- 数据方面
- 太noisy!
贡献
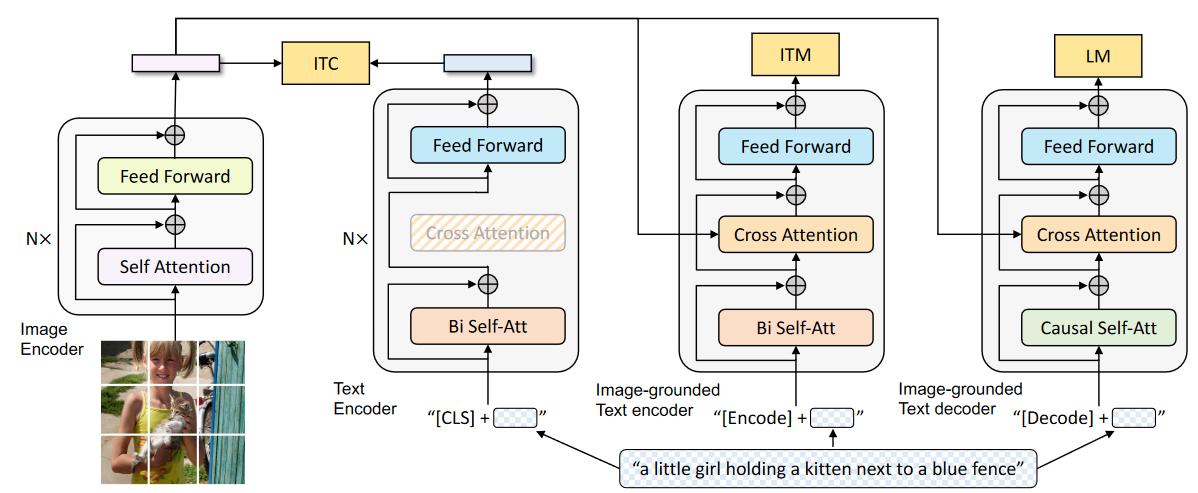
- 多通道混合的Encoder-Decoder
- 三个encoder-decoder
- unimodal encoder
- image-grounded text encoder
- image-grounded text decoder
- 三个loss
- image-text contrastive learning
- image-text matching
- image-conditioned language modeling
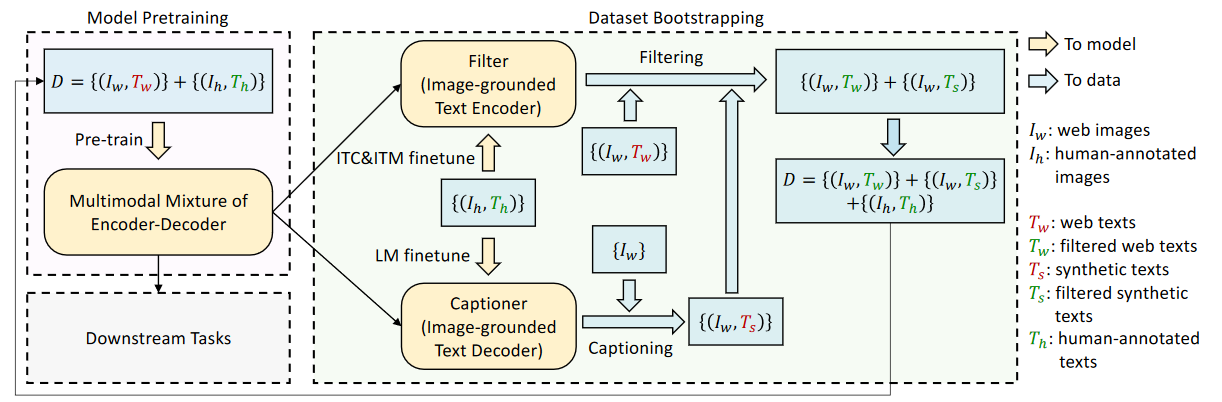
- 生成的标题caption和过滤器filter——CapFilt
- caption
- 生成web上图片的描述
- filter
- 从原本的描述与caption中进行筛选
模型结构
- image encoder
- ViT
- Unimodal encoder
- BERT
- Image-grounded text encoder
- cross-attention
- Image-grounded text decoder
- causal self-attention
- ITC
- encouraging positive image-text pairs to have similar representations in contrast to the negative pairs
- ITM
- where the model uses an ITM head (a linear layer) to predict whether an image-text pair is positive (matched) or negative (unmatched)
- LM
- 交叉熵loss
- 自回归方法训练模型使文本的相似性最大化
- 类GPT的生成,因果关系attention
- capfilt
- nucleus sampling
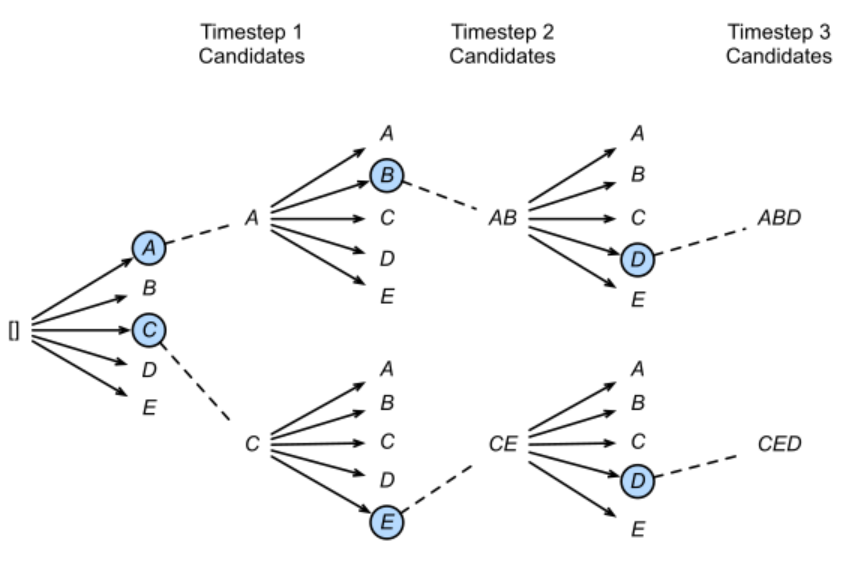
- beam search
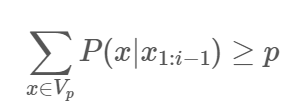

训练
- 框架
- pytorch
- 显卡
- 两台16卡
- 使用的预训练模型
- 视觉部分
- ViT pre-trained on ImageNet
- text部分
- 使用模型为BERT
base
- 优化器
- AdamW